── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.2 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.3 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsWhat is this page for?
This is mostly another practice page so I can get used to working with this package and learn about K-Nearest Neighbors (KNN).
Step 1: Get Data
For this KNN example I am going to use some data that is already in R, well documented, and clean. Iris is a very popular example data set for KNN and I will point out why this data set is popular for this type of classification method later on in this report. Let’s load a sample of it so we can see what it looks like. Head is a great command for getting a glimpse of the overall structure of the data.
Step 2: Get to know your data
Now that the data is loaded it’s a good idea to get to know the data. I don’t know what a sepal, or petal is on an iris. I’ve included an image that shows what these are for this flower and what we are measuring when comparing species.

Now that I know what we are comparing for these flowers I want to take a look at the actual data.
head(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosairis %>%
ggplot(aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(aes(color = Species))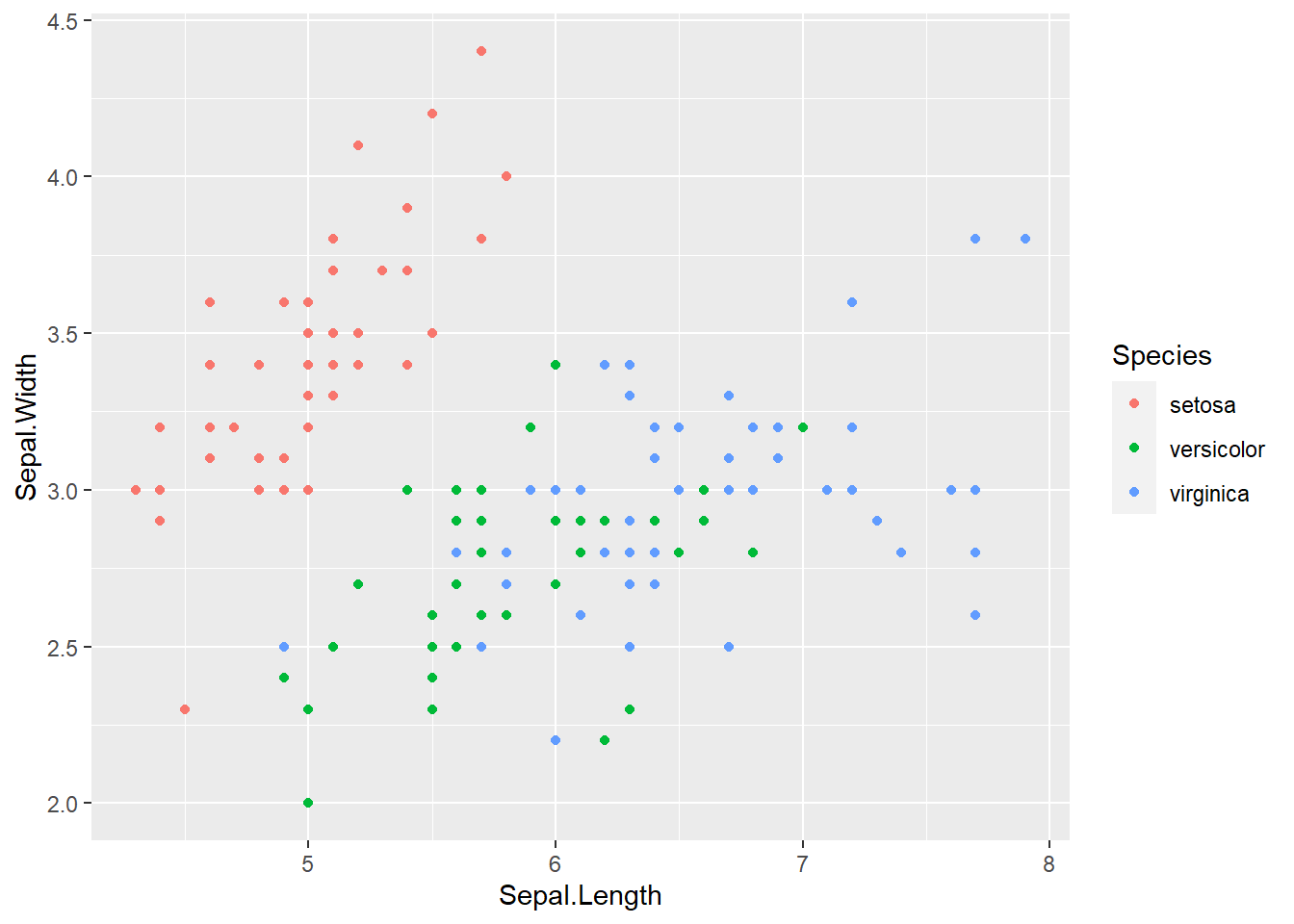
Setosa seems to be very different from the rest of the species so it should be the easiest to identify. Let’s graph these another way to see if there is a combination of data that makes it easier to tell apart veriscolor and virginica. Comparing petal length vs width seems to give some great separation for the 3 species of flower.
iris %>%
ggplot(aes(x = Petal.Length, y = Petal.Width)) +
geom_point(aes(color = Species))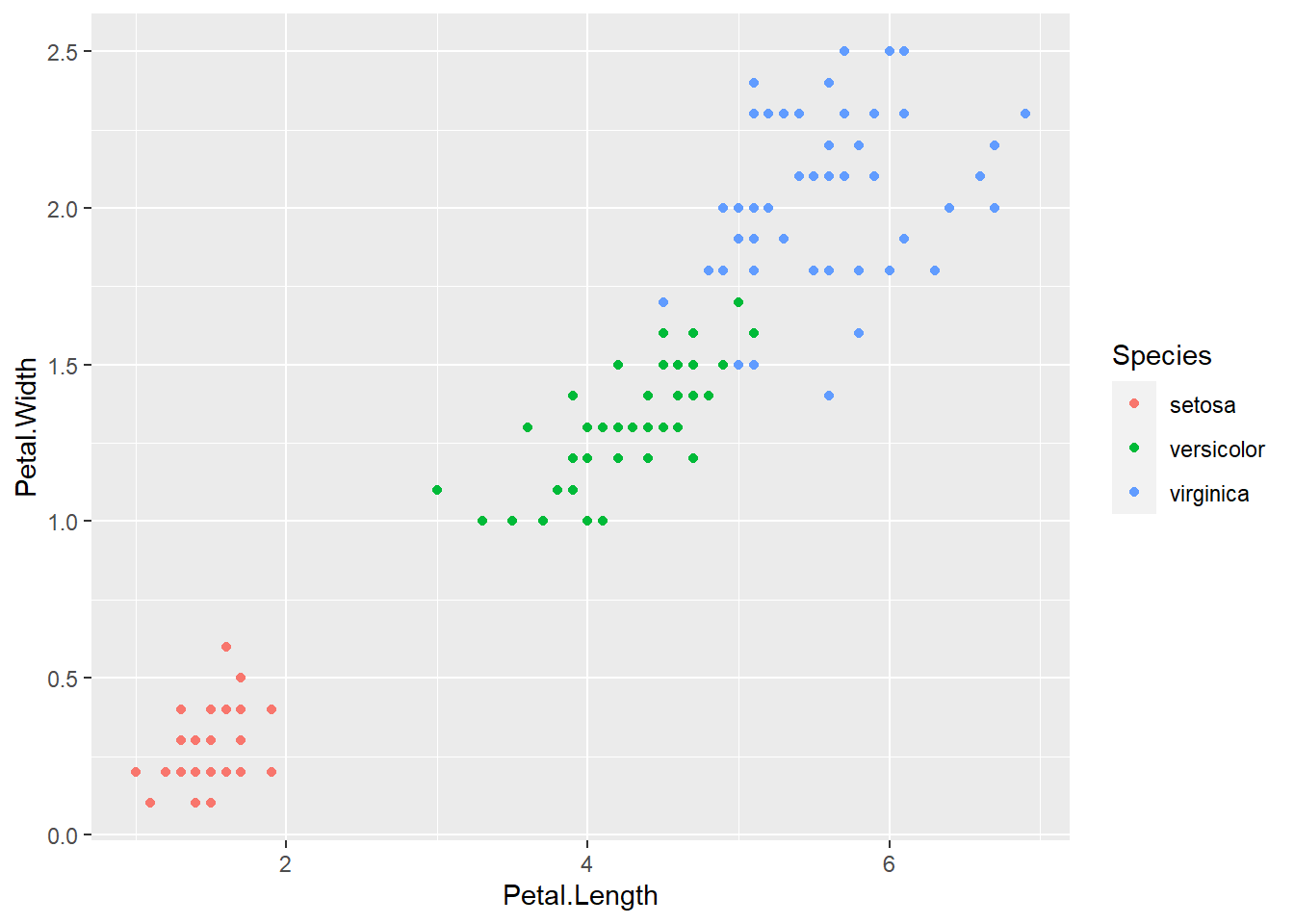
I always like to check the correlation between data to make sure I’m not missing something obvious. The first thing that I need to do with this is split the data by species and then check how the correlation of each species falls with either lapply or a for loop. Looking at this we can see that there is some correlation of sepal.length and sepal.width but the same pattern doesn’t hold true of petal.length correlating with petal.width. If you forgot what these are, look back at the picture of the flower to see why it might be that sepal length vs width are so strongly correlated.
summary(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median :5.800 Median :3.000 Median :4.350 Median :1.300
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Species
setosa :50
versicolor:50
virginica :50
temp_species <- split(iris[,1:4],iris$Species)
cor_matrix <- lapply(temp_species,cor)
for(i in seq_along(cor_matrix)) {
species <- names(cor_matrix)[i]
cat("Correlation matrix for", species,":\n")
print(cor_matrix[[i]])
cat("\n")
}Correlation matrix for setosa :
Sepal.Length Sepal.Width Petal.Length Petal.Width
Sepal.Length 1.0000000 0.7425467 0.2671758 0.2780984
Sepal.Width 0.7425467 1.0000000 0.1777000 0.2327520
Petal.Length 0.2671758 0.1777000 1.0000000 0.3316300
Petal.Width 0.2780984 0.2327520 0.3316300 1.0000000
Correlation matrix for versicolor :
Sepal.Length Sepal.Width Petal.Length Petal.Width
Sepal.Length 1.0000000 0.5259107 0.7540490 0.5464611
Sepal.Width 0.5259107 1.0000000 0.5605221 0.6639987
Petal.Length 0.7540490 0.5605221 1.0000000 0.7866681
Petal.Width 0.5464611 0.6639987 0.7866681 1.0000000
Correlation matrix for virginica :
Sepal.Length Sepal.Width Petal.Length Petal.Width
Sepal.Length 1.0000000 0.4572278 0.8642247 0.2811077
Sepal.Width 0.4572278 1.0000000 0.4010446 0.5377280
Petal.Length 0.8642247 0.4010446 1.0000000 0.3221082
Petal.Width 0.2811077 0.5377280 0.3221082 1.0000000Step 3: Preparing the workspace
So we’ve looked at the data, learned a little about what we are actually measuring, now we need to decide what we are going to do with the data. Well the title of the post is about using KNN so why not use KNN?
Prep
First I need to do a little prep to get the work space ready for the model. Loading the library that contains the code for KNN and then I’ll do this method in two ways just for fun. The first being the slightly longer method of doing things like normalizing, and splitting data by hand, and the second using the caret package to reduce the amount of handwork I have to do. Normalizing the data is important as it helps reduce the impact that large values have on a data set. The formula is very straight forward \(x_{norm} = \frac{x-x_{min}}{x_{max}-x_{min}}\). Here is a fantastic example of why normalizing data is important:  compared to data that has been normalized
compared to data that has been normalized  . In the first example getting 10 neighbors to agree would be a bit of a challenge and not obvious to us the viewer, but in the second method things are much more clear.
. In the first example getting 10 neighbors to agree would be a bit of a challenge and not obvious to us the viewer, but in the second method things are much more clear.
library(class)
normalized_iris_data <- as.data.frame(apply(iris[,1:4], 2, function(x) (x-min(x))/(max(x)-min(x))))
normalized_iris_data$Species <- iris$Species
str(normalized_iris_data)'data.frame': 150 obs. of 5 variables:
$ Sepal.Length: num 0.2222 0.1667 0.1111 0.0833 0.1944 ...
$ Sepal.Width : num 0.625 0.417 0.5 0.458 0.667 ...
$ Petal.Length: num 0.0678 0.0678 0.0508 0.0847 0.0678 ...
$ Petal.Width : num 0.0417 0.0417 0.0417 0.0417 0.0417 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...summary(normalized_iris_data) Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :0.0000 Min. :0.0000 Min. :0.0000 Min. :0.00000
1st Qu.:0.2222 1st Qu.:0.3333 1st Qu.:0.1017 1st Qu.:0.08333
Median :0.4167 Median :0.4167 Median :0.5678 Median :0.50000
Mean :0.4287 Mean :0.4406 Mean :0.4675 Mean :0.45806
3rd Qu.:0.5833 3rd Qu.:0.5417 3rd Qu.:0.6949 3rd Qu.:0.70833
Max. :1.0000 Max. :1.0000 Max. :1.0000 Max. :1.00000
Species
setosa :50
versicolor:50
virginica :50
Now to plot this data to see how it looks. While the data doesn’t look drastically different after normalization it’s always good to check to make sure.
normalized_iris_data %>%
ggplot(aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(aes(color = Species))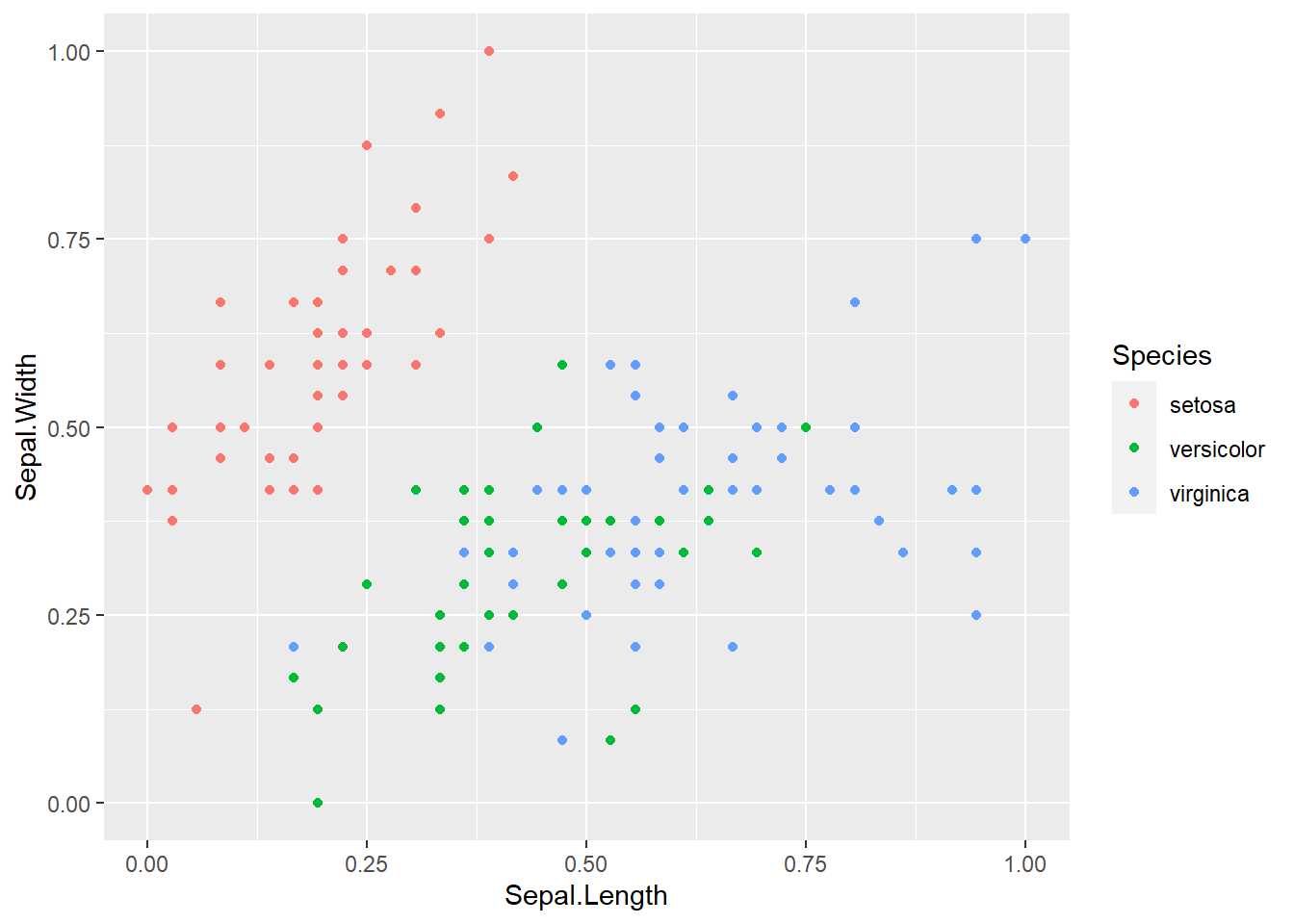
normalized_iris_data %>%
ggplot(aes(x = Petal.Length, y = Petal.Width)) +
geom_point(aes(color = Species))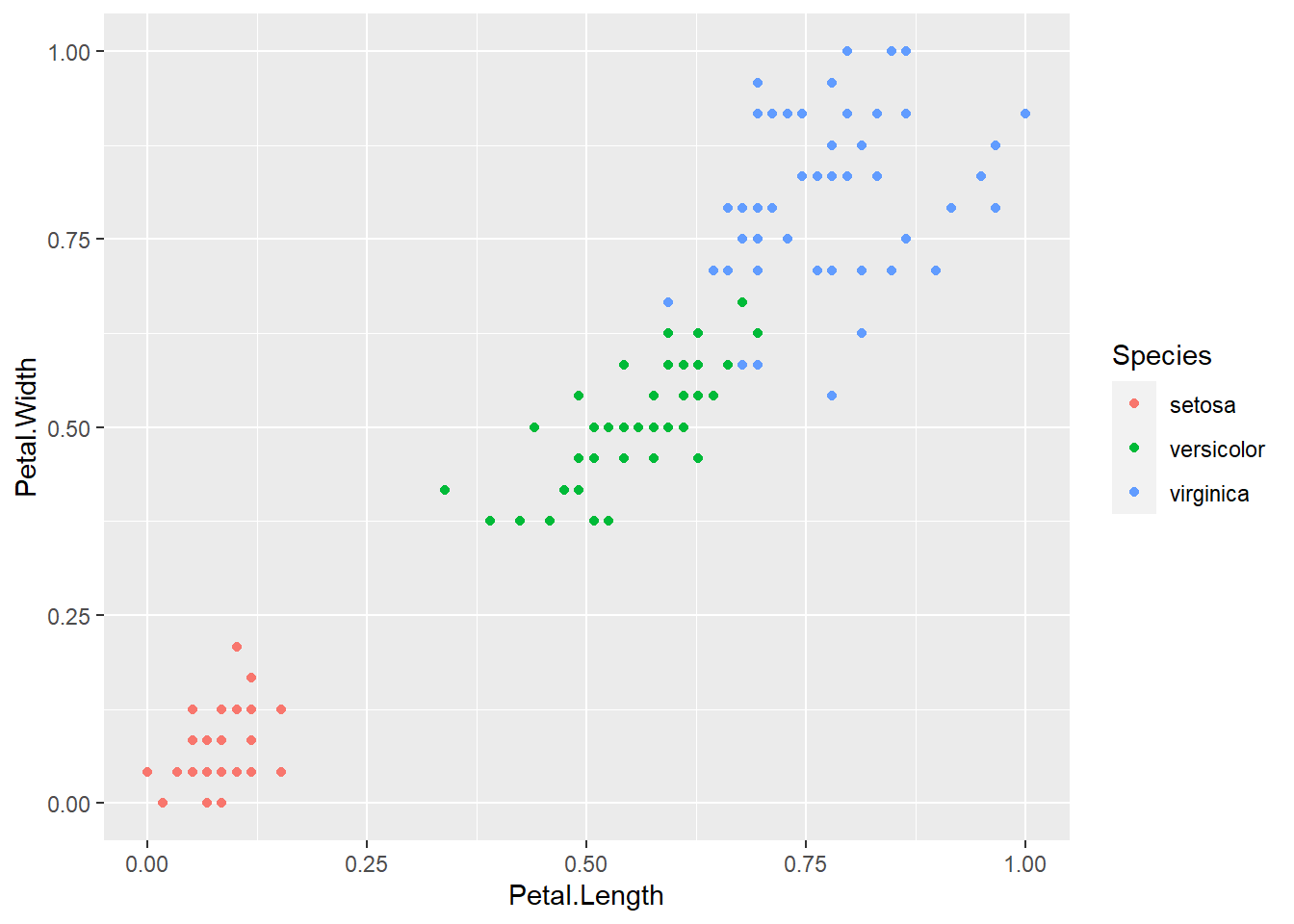
Now to separate out the training and test data, train the model, and look at how accurate the model is. I’ll also include a confusion matrix and a (much nicer to look at) cross table to help see why the model isn’t 100% accurate.
library(gmodels)
set.seed(1564)
# this gets me the indices that are going to be in test and training data sets
# using a fairly common split of 2/3 data for training and 1/3 for testing. Anything between 1/4 to 1/3 for testing is common practice.
ind <- sample(2, nrow(iris), replace = T, prob=c(.67,.33))
train_data <- normalized_iris_data[ind == 1, ]
test_data <- normalized_iris_data[ind == 2, ]
train_species <- train_data$Species
test_species <- test_data$Species
predicted_species <- knn(train_data[, -5], test_data[, -5], train_species, k = 3)
accuracy <- sum(predicted_species == test_species) / length(test_species)
accuracy[1] 0.9615385confusion_matrix <- table(predicted_species, test_species)
print(confusion_matrix) test_species
predicted_species setosa versicolor virginica
setosa 18 0 0
versicolor 0 21 2
virginica 0 0 11CrossTable(x = test_species, y = predicted_species, prop.chisq = F)
Cell Contents
|-------------------------|
| N |
| N / Row Total |
| N / Col Total |
| N / Table Total |
|-------------------------|
Total Observations in Table: 52
| predicted_species
test_species | setosa | versicolor | virginica | Row Total |
-------------|------------|------------|------------|------------|
setosa | 18 | 0 | 0 | 18 |
| 1.000 | 0.000 | 0.000 | 0.346 |
| 1.000 | 0.000 | 0.000 | |
| 0.346 | 0.000 | 0.000 | |
-------------|------------|------------|------------|------------|
versicolor | 0 | 21 | 0 | 21 |
| 0.000 | 1.000 | 0.000 | 0.404 |
| 0.000 | 0.913 | 0.000 | |
| 0.000 | 0.404 | 0.000 | |
-------------|------------|------------|------------|------------|
virginica | 0 | 2 | 11 | 13 |
| 0.000 | 0.154 | 0.846 | 0.250 |
| 0.000 | 0.087 | 1.000 | |
| 0.000 | 0.038 | 0.212 | |
-------------|------------|------------|------------|------------|
Column Total | 18 | 23 | 11 | 52 |
| 0.346 | 0.442 | 0.212 | |
-------------|------------|------------|------------|------------|
Looking at the results, by using a larger test/train set we got 2 miss classified virginica’s. When looking at the data it is obvious why 2 are miss classified. There is a overlap with the two groups where ~6 flowers are so close together that the nearest neighbors will give conflicting results so euclidean distance is not the best option, but considering this is a very flexible model, and quick to put together you could always have a more robust model to classify the difference between veriscolor and virginica.
Step 5: Using Caret package
Now that I’ve done things the long way I want to try using the caret package to see how much faster this is to put together than doing things mostly by hand. First let’s resplit the data and try out a 75-25 ratio for the split this time.
library(caret)Loading required package: lattice
Attaching package: 'caret'The following object is masked from 'package:purrr':
liftset.seed(1564)
# Split data into test and train sets
ind_caret <- createDataPartition(iris$Species, p = .75, list = F)
train_data_caret <- iris[ind_caret, ]
test_data_caret <- iris[-ind_caret, ]
# preprocess the data to normalize it
preproc <- preProcess(train_data_caret[ ,-5], method = c("center", "scale"))
# apply preprocecing to both test and train data
train_data_caret_preprocessed <- predict(preproc, train_data_caret[, -5])
test_data_caret_preprocessed <- predict(preproc,test_data_caret[, -5])
# add species back in
train_data_caret_preprocessed$Species <- train_data_caret$Species
test_data_caret_preprocessed$Species <- test_data_caret$Species
# train the model
model_caret <- train(Species ~ .,
data = train_data_caret_preprocessed,
method = "knn",
trControl = trainControl(method = "cv", number = 5),
tuneLength = 10)
# predict with model
predictions_caret <-predict(model_caret, newdata = test_data_caret_preprocessed)
# compare the results
confusionMatrix(predictions_caret, test_data_caret$Species)Confusion Matrix and Statistics
Reference
Prediction setosa versicolor virginica
setosa 12 0 0
versicolor 0 12 1
virginica 0 0 11
Overall Statistics
Accuracy : 0.9722
95% CI : (0.8547, 0.9993)
No Information Rate : 0.3333
P-Value [Acc > NIR] : 4.864e-16
Kappa : 0.9583
Mcnemar's Test P-Value : NA
Statistics by Class:
Class: setosa Class: versicolor Class: virginica
Sensitivity 1.0000 1.0000 0.9167
Specificity 1.0000 0.9583 1.0000
Pos Pred Value 1.0000 0.9231 1.0000
Neg Pred Value 1.0000 1.0000 0.9600
Prevalence 0.3333 0.3333 0.3333
Detection Rate 0.3333 0.3333 0.3056
Detection Prevalence 0.3333 0.3611 0.3056
Balanced Accuracy 1.0000 0.9792 0.9583Doing it the “long way” was just as much code in the end, but the confusionMatrix that comes with caret is much nicer and easier to understand. I do like the crossTable that I used in the first method. Not sure if I will ever use both at the same time to explain data to someone, but I am always a sucker for nice ascii art.