The last few years of politics in the US have given a lot of airtime to the discussion about fair wages and who is “overpaid in the workplace”. Recently discussion on UAF Confessions about professors needing better pay and admins being overpaid. What started as a facebook meme war made me wonder if there is an issue with pay in the UA system and if we can use statistics to detect it. This report is an exploratory report on UA pay data and if there is a meaningful link between job category and salary.
Data
# Read the data indata <-read.csv("fy22_salary_data.csv", header = T)head(data)
Campus Last First School...Department
1 UAA KING HOLLY BEI Business Enterprise Institute
2 UAA BRENNAN TOLLEFSON KATHLEEN UAA School of Education
3 UAA KEMPKER LOUISE UAA School of Education
4 UAA REDMON SARAH COH Div of Justice & Social Work
5 UAA ROBERTS JOEL VCSA Auxiliary Enterprises
6 UAA ADAME ELIZABETH COH Div of Clinical Health Sciences
Job.Category Position Pay.scale Salary Salary.Type Part.or.Full Leave
1 ADMIN 4 00_75 18397.6 NR PT 0.512
2 ADMIN 5 00_75 37211.2 NR FT 0.512
3 ADMIN 15 00_75 41059.2 NR FT 0.512
4 ADMIN 9 00_75 38667.2 NR FT 0.512
5 ADMIN 28 00_75 46696.0 NR FT 0.512
6 ADMIN 17 00_75 41849.6 NR FT 0.512
I obtained a dataset on current salaries from Lily Chohen’s website and exchanged a few emails with UA system office to ask a few clarifying questions. Initial dataset was ~6200 rows with 11 columns. One of the first things I decided to do with the data is throw out some of the columns such as B and C as they are names. I think something that merits more investigation is if the pay is fair between campuses (column A) and maybe if the pay is fair between schools (column D). Both of those questions will not be answered in this report.
The next step was to label these columns so I could have some context behind them. I threw out columns A (Campus Abbreviation), B (Last Name), C (First Name), D (School), K (leave accrument). So the new trimmed data looks like:
# Trim names out of data set and some other useless columnsdata <- data[,5:10]data <- data[,-2]head(data)
Job.Category Pay.scale Salary Salary.Type Part.or.Full
1 ADMIN 00_75 18397.6 NR PT
2 ADMIN 00_75 37211.2 NR FT
3 ADMIN 00_75 41059.2 NR FT
4 ADMIN 00_75 38667.2 NR FT
5 ADMIN 00_75 46696.0 NR FT
6 ADMIN 00_75 41849.6 NR FT
Next was the hardest part, cleaning up the dataset. I had a script read through all the job titles and pull them out. I then had to clean up spelling errors and classifications (HVAC tech 1, tech 2, etc were consolidated to HVAC Tech). The next part is to try to categorize job titles down to a few categories. I decided to simplify down the jobs down to the broad categories: Student, Faculty, Admins, Service. I did have to look up what some of these jobs did since I didn’t know off the top of my head. The general definition for each one was: Student jobs are jobs done by students and paid a student wage. Faculty are any jobs that teach, Admins are managers and management support staff, Service are any jobs that provide service to the other jobs (janitorial, coaches, broadcast media). After this I turned everything into factors.
# Turn categorical into factorsdata$Job.Category <-as.numeric(as.factor(data$Job.Category))data$Pay.scale <-as.numeric(as.factor(data$Pay.scale))data$Salary.Type <-as.numeric(as.factor(data$Salary.Type))data$Part.or.Full <-as.numeric(as.factor(data$Part.or.Full))head(data)
Admin: Managers and any department role equivalent to manager
Faculty: Anyone who is teaching
Service: Anyone who services another job (HVAC tech, janitorial, police, retail)
Student: Any job done by a student (Wood Center front desk, student firefighter)
Methods and Exploration
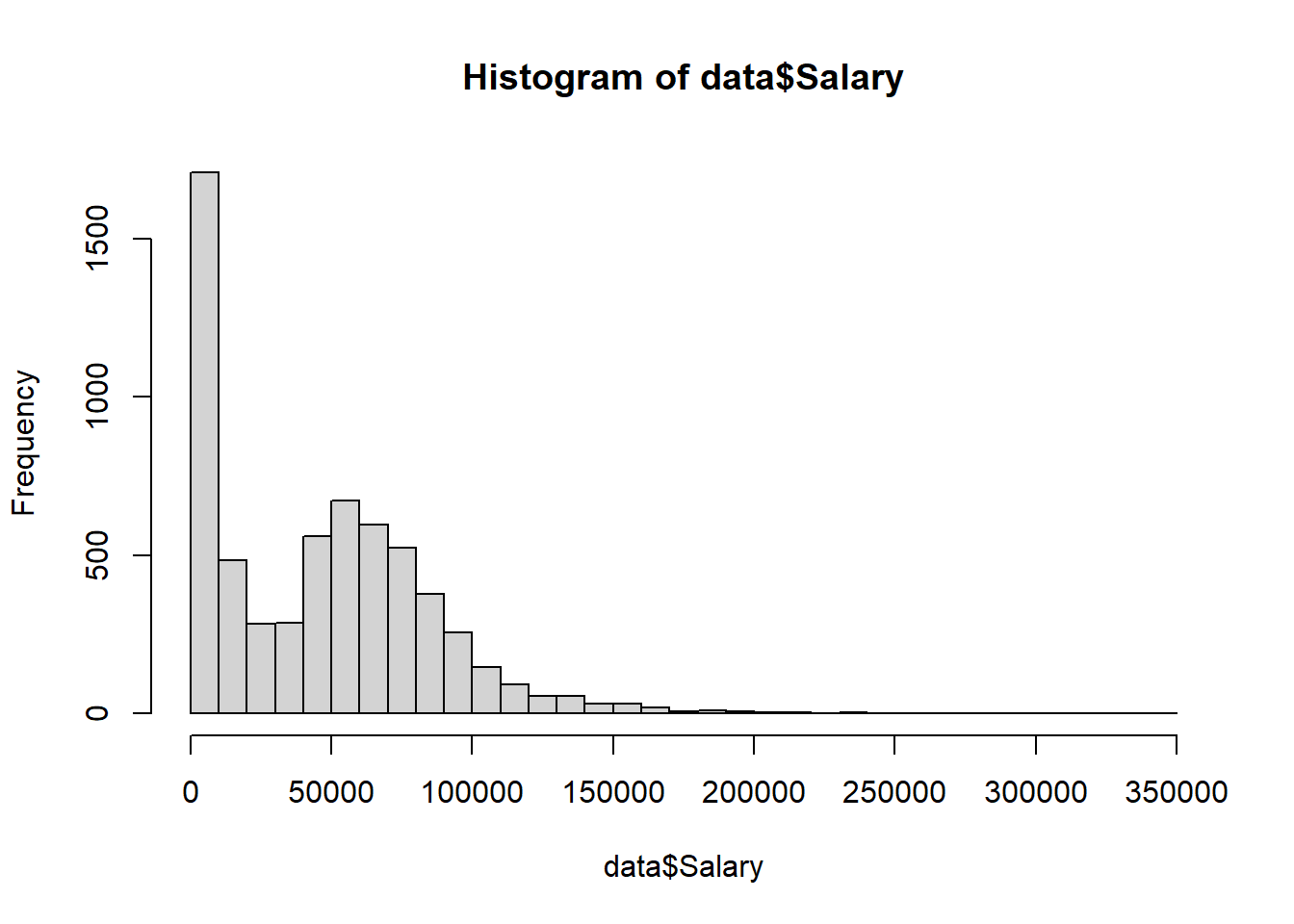
One of the first things I like to do when exploring data is just look at a histogram to see if there is any obvious trend. Since this set is a snapshot it looks like the jobs that pay little or $0 are very represented in the dataset, and you can’t see the outlier salaries because of how scaled the vertical is. Even if I adjust the bin size the extreme high end still doesn’t show very well as they are highly paid but there aren’t many above the $200k mark.
hist(data$Salary, breaks =30)
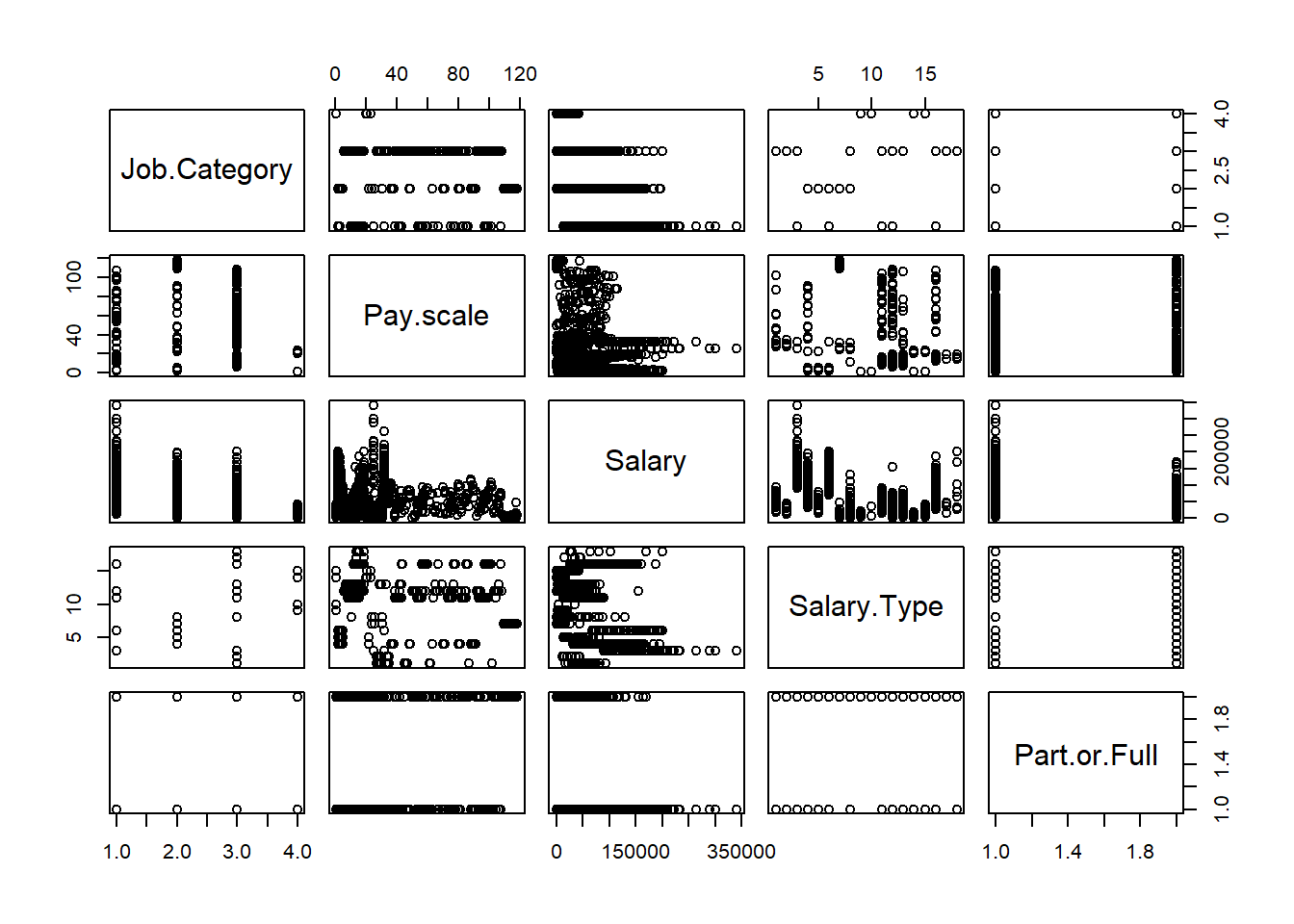
Here is a pairs plot to see if we can gain any insight.
pairs(data)
This is maybe the most interesting graph in the set. I turned job category into a factor so I could use it in various models. The code for how each job type is labeled is below.
plot(data$Job.Category ~ data$Salary)
There does seem to be some clustering in how jobs salaries differ in each category. Maybe we could use a cluster analysis model to find the relation. I will use KNN and Neural Nets and see if one is better than the other at classifying the job type based on the dataset. There will be some more graphs in the R code section at the end of this report. I will only include the useful ones.
Kmeans vs Neural Net
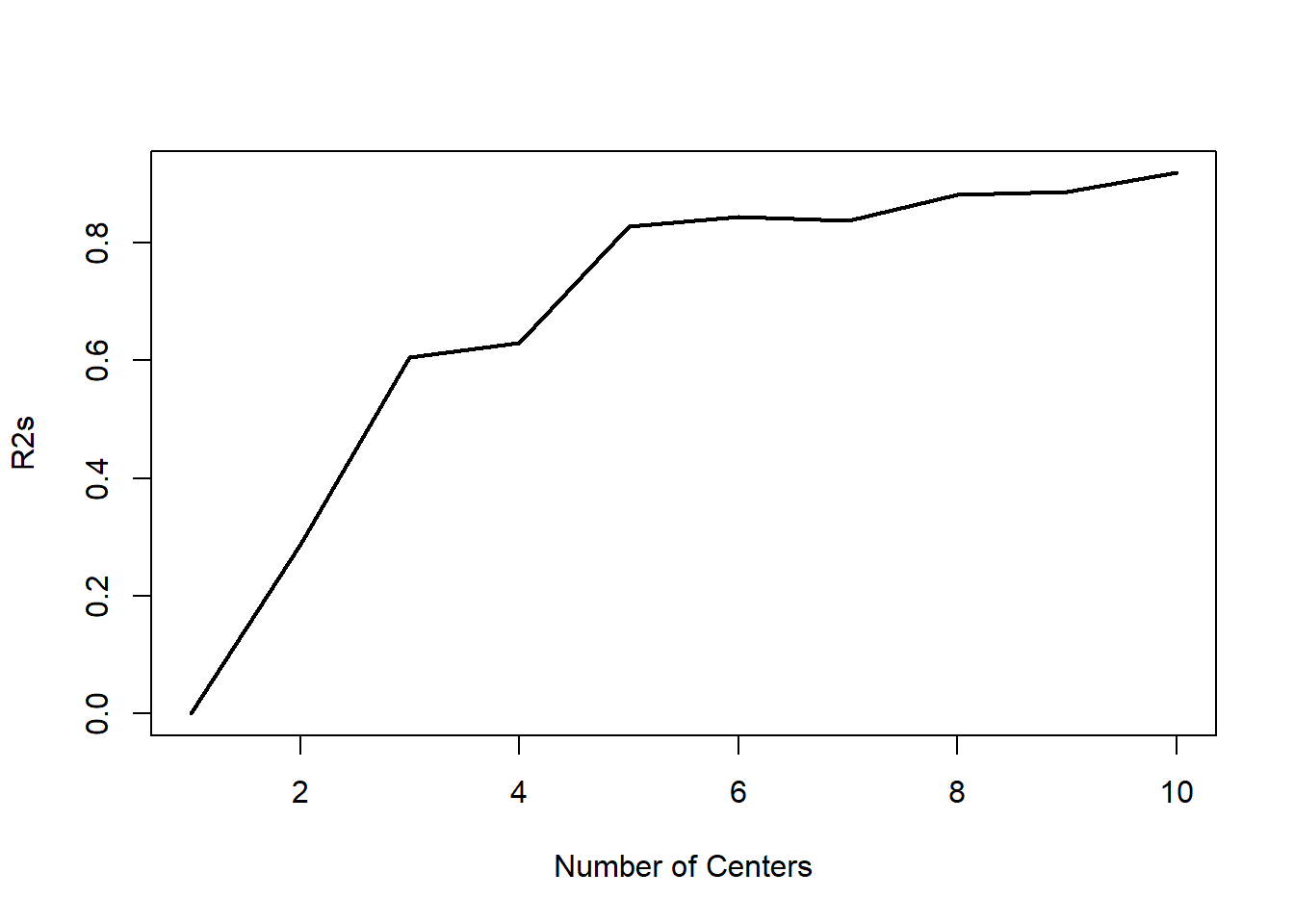
# K Meanslibrary(stats)library(class)R2s <-rep(NA, 10)# We do want to scale the data here to make sure that the euclidean distance isn't skewed from salarydata_scale <-scale(data)for(i in1:10) { tmp_kmeans <-kmeans(data_scale[,2:5],centers = i, nstart =1) R2s[i] <- tmp_kmeans$betweenss/tmp_kmeans$totss}plot(R2s, type ="l", lwd =2, xlab ="Number of Centers")
# 4 appears the be the optimal number of centers.# Now let's make sure that we generate this kmeans with the optimal number of clusterstmp_kmeans_final <-kmeans(data_scale[,2:5],centers =4, nstart =1)table(data$Job.Category, tmp_kmeans_final$cluster)
So Kmeans did a really bad job with clustering and and classifying testing data. I would not accept this model. I understand that groups 2 and 3 are close enough that misclassifying them is fairly understandable, but K means totally missed out on the student category.
# Neural Netlibrary(nnet)library(caret)
Loading required package: ggplot2
Loading required package: lattice
#split the data and train for nnsplit <-sample(c(rep(0,0.8*nrow(data_scale)), rep(1,0.2*nrow(data))))test_data <- data[split ==1,]train_data <- data[split ==0,]# tmp_nn <- nnet(Job.Category ~ Pay.scale + Salary.Type + Salary + Part.or.Full, data = data, size = c(10))# preds <- as.numeric(tmp_nn$fitted.values)tmp_nn <-multinom(train_data$Job.Category~., data = train_data[,-1])
# weights: 24 (15 variable)
initial value 6895.428152
iter 10 value 5336.135362
iter 20 value 3527.323774
iter 30 value 3437.618370
iter 40 value 3435.329873
final value 3435.024052
converged
Neural net did a great job with this data. I am less concerned about how many 2/3’s get miss classified in each other as those two groups had a lot of overlap.
Conclusions
It seems that NN did a great job classifying and K Means didn’t do as good as I’d like. Some of my concerns with this is that when classifying jobs into broader categories I could have put some in the admin section that were not administrative based on bias over their title. I also could have seen their pay and labeled them as admin due to my internal belief that admins get paid more. I think that the most important thing to take away from this exploration is that there does seem to be some relationship between pay and job category, but that need to clearly define what an admin is. If we want to talk about unfair pay we need to be explicit with our definitions.
I think a good follow-up to this exploration would be to look at the link between campus location and pay, and school and pay.